hidden
Over 10 years experience of Traceability Solutions
By pharmatrax
Category: Technoloy
 No Comments
No Comments
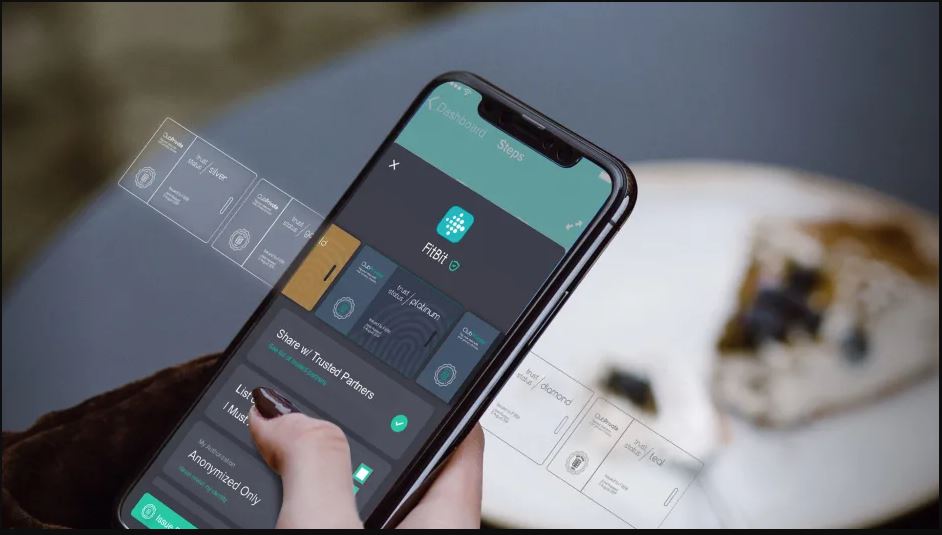
You can now make money selling your own health data, but should you?
Hu-manity.co and other firms want to help people monetize their own medical info, but the potential market raises plenty of ethical concerns for civil liberties advocates.
Selling your own health data is completely legal—if you wanted to, you could request a copy of your electronic health record from your doctor and post an ad on eBay, Craigslist, or even Facebook Marketplace. But unlike a used car or a work of art or a cherished family heirloom, your personal data isn’t something of value that you give up forever once it leaves your home. It’s something else entirely—it belongs to you, long after you sell it, until the day you die. It’s an asset that can be sold over and over, without depletion, until the demand diminishes.
So how do you figure out what this data—from every doctor, hospital, and outpatient provider you’ve ever visited—is worth? How can you put a price on a lifetime of lab test results, diagnoses, medication lists, surgeries, radiology scans, vaccinations, allergies, and blood pressure readings, especially when combined with non-medical details like your demographic information (race, age, profession, marital status) and billing history? And what if all of this data were linked to your DNA data—a uniquely sensitive and potentially precious (and as some argue, priceless) commodity?
Beyond those questions, how do you make sure that people understand the consequences of selling their data and how it will be used by any buyer? And how do you make sure that the poor and desperate aren’t exploited by the market for such data?
These are all questions that remain without answers for a market that remains to be realized. But it’s around the corner, and some companies and lawmakers have been busy laying the groundwork for this brave new world.
One company is lobbying state legislatures in Maryland and Oregon to make it easier for sellers and buyers to find each other. Hu-manity.co attempts to connect users of its app to companies and organizations using a “consent as a service” model: that is, extracting medical information from users who “consent for privacy” and “authorize for permitted use.”
“Most people who have a data privacy conversation are having it either from a pro-consumer perspective or a pro-corporate perspective,” says Hu-manity.co CEO Richie Etwaru. “Corporations give free services to consumers in exchange for monetizing their data. So if consumers don’t want their data monetized, they can’t have free services. The issue right now is that there’s not a choice. Choice would be fantastic.”

Such proposals raise concerns among civil liberties advocates. Chad Marlow, a senior advocacy and policy counsel at the ACLU, takes issue with this proposed legislation’s attempt to use state governments to generate a customer base for these companies—in effect, to generate leads. “These companies are actually seeking the government’s help in creating a market for it, and I think that’s where it feels particularly different and offensive,” he says. “They can inject themselves into the process at a very convenient, low-cost stage by mandating doctors to have to tell their patients, You can sell your information, and by the way, ‘Here’s how you do it. Here are the companies that will help you do it,’” he says. “The government should be [ . . . ] empowering people to say yes or no, not creating a marketplace to make it really easy to say yes.”
In February, California Governor Gavin Newsom announced he will look into a ‘Data Dividend’ (aka ‘digital dividend’) plan for consumers as a payout from Big Tech. “Your data is being monetized every single nanosecond. And to the extent it’s been monetized and it’s yours, I think in some way, shape, or form, you should be rewarded,” Newsom told Axios in June. In January, 40 lawmakers in Oregon signed onto a bipartisan bill that would have enabled consumers to monetize their de-anonymized medical data.
“The Oregon bill was indeed the perfect Trojan horse for the consumer,” Etwaru says, referring to an op-ed Sarah Jeong penned for the New York Times‘ Privacy Project. “It was exactly what the consumer needed: a concept that introduced contrast to the system so that the lobbyists, the politicians and the corporates can no longer hide—because yes, you own it. Ownership by definition—without clarification—is an incomplete legal contract. You have to clarify the type of ownership. We introduced property, and it turned the lights on, and now, we see who’s who. And I couldn’t be happier.”
Marlow hopes that Newsom will “abandon” his support when he “becomes better informed” on the issue. “We don’t need legislation out there that, if you want to be honest, let’s call it: How to make the tech industry even more money at the expense of poor people’s privacy.”
Etwaru, who was born in Guyana and grew up in the Bronx, argues that these class divisions aren’t a new or even dangerous thing. “Not everybody was born on top of oil. But everybody has data. And this is why it has to be owned—because if not, it’s going to be siphoned out by the current sovereignties in power and create even more inequality.”
“If you look at the people who’ve made money from data in the hundreds of millions or billions, it’s white males. Look around,” Etwaru says. “This is the new natural resource. This is actually the opportunity to level the playing field.”
While the Electronic Frontier Foundation overall supports the new California Consumer Privacy Act, it is pushing for amendments to remove pay-for-privacy schemes (the law allows companies to offer “incentives” (discounts or deals) to people for their data, including “payments”). It also allows companies to do the opposite: to actually charge people a fee if they opt out or refuse to share their data or have it collected.
“They actually have the audacity to suggest that they are pro-privacy. They’re not,” Marlow says. “If someone is selling something and it violates people’s privacy, the thing that you do is pass a law to prevent them from selling it—not figure out a way to make a few bucks for the person who’s losing their privacy.”
In response, Etwaru fires back by questioning the ACLU’s motives: “If the ACLU is standing against any conversation about ownership where humans can have control of their data to protect the species from mass manipulation, then the ACLU is no longer the American Civil Liberties Union,” he adds. “It’s the American Corporate Liberties Union. And I want that quoted.”
One proposed law that outlines a non-monetized way to protect consumers’ privacy is the It’s Your Data Act in New York’s state assembly. And in March, Louisiana Sen. John Kennedy introduced similar legislation into Congress: the Own Your Own Data Act.
THE RISKS OF MONETIZING GENOMIC DATA
Genetics describes how genes work and how they influence heredity and dates back to the experiments of a mid-19th-century friar-turned-scientist who tinkered with pea plants. Genomics, the field of biology focused on an organism’s complete set of DNA, is a far newer field. The data in your genome is forever tied to you, as a unique identifier. Once you give up this data, you lose your anonymity because it nails you down and pinpoints you in a way that’s far more difficult to avoid than other technologies (after all, you can cover your face or wear sunglasses to avoid facial-recognition cameras).
In the wake of all the recent privacy scandals involving social media platforms sharing user data with third parties and advertisers, the potential misuse of genomic data represents the next chapter. Millions of people are giving up personal information without truly understanding the consequences of that sharing.
FamilyTreeDNA, for example, shared users’ genetic information with the FBI and law enforcement without notifying its users. According to enrollment numbers compiled by Dr. Leah Larkin, some sites like the open-source GEDmatch—which law enforcement used to catch Joseph James DeAngelo, the Golden State Killer, and at least five other cold cases—likely aren’t growing as fast as they used to because “they know law enforcement is using the database for criminal investigations.”
“That person was located because users uploaded their genetic information to a third party website called GEDmatch. And giving users’ ownership over their data doesn’t reduce the risk of this happening again. In a way, it actually could make it more likely,” says Meg Young, codirector of the Critical Platform Studies Group at the University of Washington. “It’s the family members uploading their own information that caused this,” she adds.
The company now holds over two million DNA samples in its database, which means that nearly every American of European descent has a third or fourth cousin inside its system. These are people who we’ve probably never met, of course. Researchers at the University of California, Davis calculated that a large number of people have at least one “high confidence” cousin in GEDmatch, and, like FamilyTreeDNA, nearly everyone has a third or fourth cousin inside its system. “Though DeAngelo’s capture is widely celebrated, people are also understandably surprised that the decisions of third or fourth cousins can potentially expose one to surveillance,” they wrote.
It’s worth remembering that you share your genes with your biological family: the information doesn’t belong to you and you only. It’s a secret that, if shared, affects other people, too. Genetic data on genealogical websites displays information about your relatives and the people they are related to, even though they don’t give consent to make that information public. So, is that a potential invasion of their privacy?
Amid a public outcry, FamilyTreeDNA recently revealed that it changed its privacy policy without notifying its users months after modifying its terms of service to become GDPR-compliant. According to a February 2019 newsletter signed by FamilyTreeDNA president Bennett Greenspan, in May 2018, the site’s terms of service read: “You agree to not use the Services for any law enforcement purposes, forensic examinations, criminal investigations, and/or similar purposes without the required legal documentation and written permission from FamilyTreeDNA.”
Yet the company did just that, Greenspan admitted. “Without infringing upon our customers’ privacy, the language in the paragraph referring to law enforcement was updated in December, although nothing changed in the actual handling of such requests. It was an oversight that notice of the revision was not sent to you and that is our mistake,” he wrote.
In the letter, Greenspan further claims that the terms of service will return to the May 2018 version—but there’s no guarantee that it won’t be changed again at some point, of course.
Other “spit sample” genealogy databases like Ancestry.com and 23andMe operate similarly: like any site, the terms of service and other policies change without you knowing about it. Ancestry.com’s law enforcement guidelines state that its policy is to tell its users about police requests unless a court order forces it to keep quiet. But that isn’t even necessary: according to its policy, “For all requests, we may also decide, in our sole discretion, not to notify the user if doing so would be counterproductive and we are legally permitted to do so.”

These sites must comply with any court-ordered search by law enforcement. That means the data is up for grabs once an officer convinces a judge to issue a warrant—which can happen quite quickly.“The government is subscribing to use genetic databases right now for law enforcement purposes, which is generally a good thing,” says Nebula Genomics cofounder Dennis Grishin, who recently coauthored a correspondence paper in Nature Biotechnology on genomic data privacy. “But it still raises a lot of concerns, because it’s essentially perceived as the privacy of millions of people being violated in order to identify a criminal. And we just think it can be done in a better way, where the individuals who own the data—their permission is asked first before the data is used.”
One chilling example of a state using genetic data for surveillance is China’s “Physicals for All” campaign in Xinjiang to control the region’s Uighur Muslims. The policing program collected eye scans and DNA samples from nearly 36 million people between 2016 to 2017. In some cases, officials also recorded voices and fingerprints. (However, the Xinjiang government said in a statement that it did not collect DNA samples.) The system depends on large, public DNA databases and technology made in the U.S. and around the world. Equipment made by Massachusetts-based company Thermo Fisher was sold in China to enable police to identify and distinguish between DNA samples—including by ethnicity.
What’s more, the genetic data collected and sold by companies like Ancestry.com and 23andMe—which just closed a $300-million drug development contract with GSK—is skewed towards the typical customer, who tends to be white and affluent. This bias is baked in—and it limits what this data can do and who it is for. A recent Cell paper found that 78 % of genome-wide association studies focused on European ancestors, even though this group represents just 12 % of the global population. (The other 12 %: 10 % Asian, 2 % African, 1 % Hispanic, and less than 1 % ‘other.’)
This has “important implications for risk prediction of diseases,” the authors wrote, such as Alzheimer’s, diabetes, and heart disease. It also means that many people who take prescription drugs aren’t getting a fully functional and personalized treatment—that is, for the 88 % of the world who don’t have European ancestry, these drugs inherently have limited potential. We also know far less about genetic mutations in people with non-European ancestry.
One genome-driven algorithm consistently prescribed too much Warfarin for African American patients, one study found, which increased their risk for bleeding. Another study found that a genetic test for schizophrenia gives people with African ancestry a risk score that’s 10 times higher than people with European ancestry. It’s not that schizophrenia is far more common in people with African ancestry—the test is warped because the data is incomplete. And that can engender a racist medical practice. It can even make diseases more common and more deadly. (For example, African-American men die of prostate cancer more often than white men do—about twice as much.) This makes it especially tough for physicians to help patients of color untangle nature from nurture—that is, what about their condition might be due to biology, and what is driven by environmental factors.
THE ALLURE—AND LIMITS—OF DATA ‘OWNERSHIP’
Your genetic information isn’t something you own: it’s who you are, intrinsically. At least that was the idea when the word genetics was somewhat begrudgingly coined just over a century ago by a British biologist who, as the Oxford English Dictionary helpfully notes, wasn’t exactly a rock-star scientist. But he did leave us with this word we’ve inherited, cut from a longer word with a Greek root that means “offspring.” It’s a thing that’s created, then passed down. It’s not something you give up or give back. It’s not only what you’re made of—it’s something you can’t part with.
Alex Zhavoronkov, CEO of Insilico Medicine, sees things differently. “Imagine it’s the days before electricity, and we need to price electricity in order to be able to create a market. It’s the same with data,” he says.
“If the people who donate this data are closely related, [it] will be more valuable than if they are completely separated,” he adds. “You know how we price options and derivative securities? So now, imagine if we had similar rules for doing this with data in the context of medical discovery and in the context of value creation.”
“In the future, I have no doubt there will be lots of [financial] derivative products on human data,” he adds.
In a new paper published in Cell’s Trends in Molecular Medicine, Zhavoronkov partnered with George Church, a Harvard Medical School professor who cofounded Nebula Genomics, a consumer-facing testing company.
“We think that there are potentially justified reasons to be concerned about genetic data privacy,” says Grishin, the Nebula Genomics cofounder. “We’re still in the very, very early stages, so we don’t know yet what the future will bring.”

There’s even the potential for companies to develop targeted advertising based on your genetic data. “If Facebook—which already has all of these privacy issues from collecting personal information about you, targeting you with ads—then adds your genetic data to it, it just becomes a privacy nightmare,” Grishin says. “That’s a use case that I find very concerning, but it was already proposed by some startups. And with our focus on privacy, we want to make sure that this just doesn’t get out of hand.”The paper calls for a new economy based on “human life data”—that is, monetizing your medical information, including the results of your at-home, spit-sample genetic tests. Zhavoronkov and Church agree that the pricing and valuation of this sensitive health data should be handled carefully and securely, and a blockchain-based system with a health-specific cryptocurrency is one way to go. But Zhavoronkov sees reason for concern—that is, potential privacy issues—for machine-learning-led companies that use non-anonymized genomic data that can identify customers one by one.
“Because genomics data was overhyped in the early 2000s and even today as ‘pure play’ genomics data, these [pharmaceutical] companies focus on acquiring [it],” Zhavoronkov says. “Currently, a lot of people give genomic data a lot of value just because it’s sensitive, it’s difficult to get, it needs to be consented, you need to spend a lot of money to sequence it, you need to process the sample, you need to obtain the sample.”
Though pharmaceutical companies try to acquire massive genomic data sets alongside other health data—clinical histories, medical records, biopsies of cancer patients’ tumors, and more—most genome-specific information isn’t as valuable as most pharmaceutical companies believe it to be, Zhavoronkov says, though he admits this isn’t a popular opinion.
“I think that genomic data is overrated because there are reasonably few drugs on the market that came out of [it],” he says. Pharmaceutical companies are motivated to hoover up this data because it aids in identifying protein targets for certain patient subpopulations. This month, GSK’s $300 million, four-year partnership with 23andMe launched an option in beta to certain users. “But the jury is still out in terms of how effective the strategy is going to be. [ . . . ] We haven’t seen any tangible output [from] this partnership yet,” Zhavoronkov says. “It’s very easy to hype something up, but it’s not very easy to deliver something on the market.”
But how does “human life” become data? It becomes known via a company’s testing—the analysis of your chromosomes, DNA, and more. This step is worth remembering, University of Washington researcher Meg Young says.
What separates Nebula Genomics from firms like 23andMe is the cost to sequence a user’s entire genome. Despite the hefty price tag, Nebula Genomics claims it will give people access to this information about their own DNA for “free.” (Just as Facebook is “free.”) So who are its customers, really?
“Firms are potentially subsidizing the cost of whole genome sequencing for the kind of access they’ll get from users,” Young says. “It’s being subsidized in order to be created, and the [pharmaceutical] companies are going to get a high degree of access and visibility into whatever they need about it—and then, people are paid after the fact.”
The payout itself is asymmetrical—and the geometry may surprise you. The first companies that experimented with personal data marketplaces were Datacoup, Handshake, CitizenMe, Digime, and Meeco, in 2013, 2014, and 2015. One reporter for the BBC attempted to make money off of their data and found that it wasn’t worth much at all. Compare that to these economists’ predictions about Datacoup’s rosy future: “While Datacoup remains small compared with Facebook, we suspect the market is going to grow, considerably, for companies that employ stricter data safeguards and reward their users for the data they are willing to share.” In its FAQ, Datacoup explains, “the price for your data is the sum of all your active attributes. We anticipate these values to fluctuate and increase as the marketplace grows and matures.”
The problem with the idea of “data ownership” is that it’s a promise that companies like Nebula Genomics and Hu-manity.co can’t keep, Young says. “Ownership as a model is more of a talking point than a meaningful path forward for data governance,” she says. That is, the rhetoric might sound appealing to consumers who place a high value on privacy, but the claim of “ownership” can’t hold—it just isn’t sustainable. Data is easily copied, of course, and it’s nearly impossible to take back once it’s been copied by someone else, even if the permission to share is revoked.
“Even though people are being told they ultimately own their data, they’re not paying for it to exist. And it’s being shared on someone else’s platform,” she explains. This means you should be skeptical if a company claims it can give you the power to “own” your data—and it can end up being an empty promise, Young adds. “They’ve got access to a very granular copy of it in order to get exactly what they want out of their analytics. At that point, does it really matter who owns the data? Because they’re getting the whole kit and caboodle to look for what they need.”
Instead of data ownership, Young suggests thinking about data in terms of access—because access is a specific type of control that users can actually reliably retain.
“It’s who can access your data, to what end, and who has the ability to make decisions about that access,” she says. “The idea of data ownership attempts to speak to those concerns, but I think it obfuscates them.”
Marlow says the ‘data-as-property’ model isn’t necessary to help people reliably and safely manage their personal information—that is, share it when they want to, or choose to keep it private. “The only thing the property model does is allow businesses to monetize people’s private data. The best way to protect this highly sensitive information is to not make it property, to not treat it as property,” Marlow says. “There is something very, very different about selling your private data than selling a car.” (Or a kidney.)
Hu-manity.co’s Etwaru agrees that property is an imperfect model—for now. He sees data as a “non-rivalrous” good. “With data, multiple people can use it at the same time without rivaling the value that the other person gets. “I’m not saying that in the future, human data is going to be human property as in the title for my car or my house,” he explains.
Young is also skeptical of Hu-manity.co’s position, which claims that “consumers can claim a property interest on inherent human data”—that is, that people can actually choose to share their medical record, treatment history, diagnoses, billing records, list of filled prescription medications, and test results with a button—or to keep this data private. Will this action of “choice” truly “hold data markets accountable to your wishes,” as a December 2018 marketing video claims?
“Our mission is to GIVE YOU CONTROL,” an animated video posted in December 2018 claims. Under a lush, dramatic soundtrack, the words “We will fight FOR YOUR RIGHT to own your data AS PROPERTY” slide under a triumphant woman painted in a rainbow of colors, one arm brandishing a staff, the other holding a paper scroll tight to her chest. It continues: “When you own something, you can control how YOUR PROPERTY is used. Now, you are cut INTO THE DEAL.”
This pitch to lawmakers uses privacy-first language, which might seem like a solution or even a public service—but it’s actually a trap, Marlow says.
“It’s hardly uncommon for an industry selling a product to not be forthcoming about its downsides,” Marlow says. “I don’t want to stretch it too far, but I think [one example would be] the people who sold the no money down, no income check, ballooning payment mortgages: the companies that caused the financial crisis.”
“They didn’t actually care about people reaching their American dream of owning a home. That wasn’t their motivating factor,” he adds. “They wanted to make money off the loans.”
The crisis, of course, went even deeper. With these loans, these firms created a new product to sell—a derivative asset unto itself, packaged, bundled and split, split, split. Health and medical data could follow suit, once it’s priced as a thing to sell.
Could this one day drive consumers to act just as they did before the 2008 crisis, driven by a similar set of circumstances? Millions of low-income home-buyers signed onto mortgages they couldn’t handle because the lenders were incentivized to sell. With medical data, the asset that’s created isn’t a signature on a mortgage—it’s a patient in a waiting room, or waiting for the results of an at-home test, spending money to complete a procedure and submit the data into an app. The product that’s bought relies on the healthcare system—a mix of workers, buildings, technology, talent, time. It’s a succession of opportunity costs, split over and over like derivative mortgages.
The stakes are high. “Who owns the data will control the world,” Etwaru says.
This story has been updated to better reflect the Electronic Frontier Foundation’s position on the California Consumer Privacy Act.


